Having access to an accurate forecast is very beneficial for businesses. If used correctly, it can provide better margins, increase market shares, and many other positive results. At a more tactical level, it can help reduce the costs associated with meeting the customer demand and make the supply chain more efficient. For instance, it can reduce the ratio of unplanned inventory to the total inventory. As a result, companies are interested in making the forecast as accurate as possible.
Companies often use the Coefficient of Variation (CV) as a measure of forecasting for a particular time-series data. Much has been written about the usability of this metric to measure forecastability, some more positive than others. My personal view is that it is helpful. It is easy to calculate, explain, and understand. Further, there is the practical matter that it is immensely popular and probably exists in most forecaster’s spreadsheets or programs. And finally, no other simple calculation is available to practitioners to have any sense of forecastability of their data. As a result, I feel this measure will stick around for a while.
In my consulting assignments, I always ask practitioners to estimate the portion of the data that is high CV (> 0.5) before looking at the data. I want them to estimate this at the material-location level, as it is at this level that the supply chain practitioners are often trying to improve the forecast. I have often found that this is underestimated. In the late 90s, it was not uncommon to casually state that the Pareto’s law (80-20 split) would be followed. In most cases, the actual observation was closer to a 65-35 split for low to high CV. However, I find that the ratio of data where the CV value is high has been steadily increasing over the years. One of the reasons is the ability to make highly specialized products has increased leading to ‘the long tail’ effects as very nicely described in the eponymous book by Chris Anderson.
To put some real data behind this, we collected some data via a survey. The results are summarized below. N/A means data was not available.
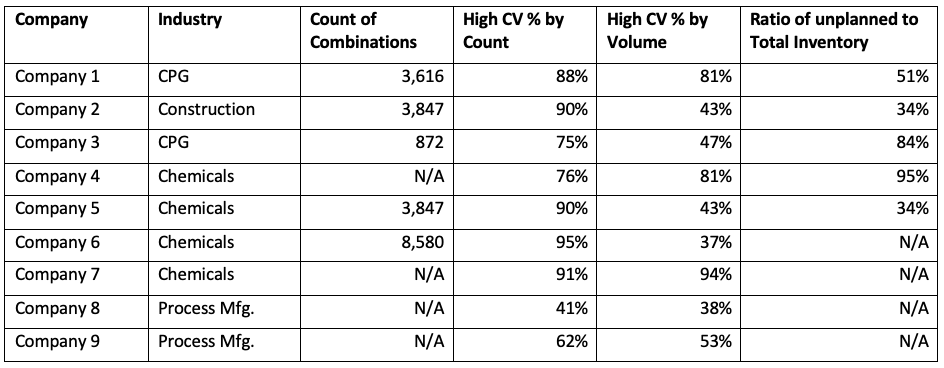
Let us summarize some observations for this admittedly small sample size.
- The percent of High CV combinations by count ranges from 41% to 91%(!).
- The percent of High CV combinations by volume ranges from 38% to 94%(!).
- The ratio of unplanned inventory to total inventory is quite high. In 3 out of 4 cases, it is more than 50%.
Now, it will be a good thing to conduct a survey for a large sample size. Perhaps such a study is better conducted by people who specialize in the science of surveys. I am however ready to summarize the following:
- Very likely, most companies are underestimating the portion of data that is not forecastable. If true, this would mean an unrealistic expectation of forecast accuracy. Suggestions:
- Be data-driven about this and use it to temper the expectations.
- Look into techniques such as probabilistic forecasting to create a better forecast.
- Deploy advanced supply planning techniques to control overall costs.
- There is a price to be paid for this variability in terms of too much unplanned stock. This fact was also borne out in the data analysis presented in this blog. Suggestion:
- Consider rationalizing your product portfolio.
In the next blog, I will talk about how to create realistic expectations of forecast accuracy targets for a company.
Enjoyed this post? Subscribe or follow Arkieva on Linkedin, Twitter, and Facebook for blog updates.

About the Author: Sujit Singh
As COO of Arkieva, Sujit manages the day-to-day operations at Arkieva such as software implementations and customer relationships. He is a recognized subject matter expert in forecasting, S&OP, and inventory optimization. Sujit received a Bachelor of Technology degree in Civil Engineering from the Indian Institute of Technology, Kanpur, and an M.S. in Transportation Engineering from the University of Massachusetts. Throughout the day don’t be surprised if you find him practicing his cricket technique before a meeting.

About the Author: Manjeeth Vijayan
Manjeeth A Vijayan is a Senior Consultant at Arkieva, India. He is responsible for analyzing client’s supply chain processes, configuring and implementing Arkieva software, thereby, helping clients improve efficiencies in their supply chain planning. He received a Bachelor Of Technology degree and went on to earn his masters in Industrial Engineering from the National Institute Of Industrial Engineering, India. He is also an APICS certified CPIM (Master Planning of Resources) certificate holder. Other than supply chain, traveling and hiking excite him these days.





