Summary: This material provides some basic guidelines to determine if the data is quantitative or qualitative with a focus on areas in the shadow where it is initially not clear. With analytics the rage in executive discussions, it addresses a question that is often a stumbling block to a successful outcome. Second, it acknowledges one often applies quantitative methods of analysis to qualitative data and at times this may provide insight. However, it can also mislead an organization.
A few days ago, a friend told me “It is great that data science is all the rage and it will transform any organization into a finely tuned machine, but—in most meetings, I am in with executives, we lack a simple description of the difference between quantitative and qualitative data.” I observed this occurs for good reason since the difference has layers of complexity and a one-sentence answer will be counterproductive over time. He challenged me to produce a basic guideline. Below is my attempt. I did offer this one-sentence description: if you can legitimately add and subtract the numbers, or find their average, then this is quantitative data; if not the data is qualitative. He immediately responded – this “legitimate” term sounds “lawyerish”.
First, we have three (not two) major types of data:
- Quantitative – a regular number that either measures an attribute (for example blood pressure) or counts the number of occurrences (sales of chocolate chip ice cream)
- Purely descriptive – it was a beautiful sunset as we looked upstream from the bridge
- Qualitative – this will be the most complicated and includes: a classification that is selected from a set of options (categories); a scale detached from any physically measurable attribute requiring a subjective or self-assessment; and a preference ranking. Now hold on for a moment– this was supposed to be easy to follow and you used some fancy words in the last sentence. Three examples will tide us over until we get to the section on qualitative data.
- Categories: the best known is yes/no (binary) – for example, if a person does or does not have a certain disease. Other examples include a person’s current marital status: never married, married, widowed, or divorced; if the meal is classified as hot or cold.
- Scale – this is a common approach used in pain assessment where you rate your pain on a scale of 1 to 10 where 1 is no pain and 10 is very high pain. Observe the pain scale has an anchor at each end, a score of 6 implies more pain than a score of 3, but a selection of a score requires self-assessment. That is, we do not yet have an independent method/tool to measure pain at neurons. This type of scaling is common in food and hospitality to measure customer satisfaction, where a common scale 1 is very dissatisfied, 2 dissatisfied, 3 neutral, 4 satisfied, and 5 very satisfied. Observe the “numbers” serve more like labels.
- Ranking (order): in food and hospitality asking a customer to rank or put lunch options in their preferred order. For example, if the options are salad bar, sandwich, hot entry, or burger. One ranking would be a hot entry (1), salad bar (2), sandwich (3), and burger (4).
Yes, there are “numbers” in (b) and (c), but they are really labels.
Second, there are two primary types of quantitative data
- “Regular Numbers” this measure an attribute of some item. In a health care setting, examples are weight, height, blood pressure, heart rate, age, the oxygen level in blood. For food service: the amount of time a person waits to check out. In supply chain, the capacity available, estimated demand, time to ship a product from one location to another. These regular numbers are more formally called “rational” numbers: 3, 4.2, 10.44, -9.3, etc. It is legitimate to add them together or divide one by the other. For example, I took my granddaughter in for her four-year-old physical, her height is 41 inches and my height is 74 inches, so she is 55% (41/74) as tall as I am.
- One caveat, we won’t spend much time on, is understanding the scale for measuring. Feel free to skip this bullet. The best-known example is metric (centimeters – cm) and English (inches). My granddaughter is 104cm tall and I am 188cm in height. The ratio of heights remains 55% (104/188). For both systems “0” has the same meaning – no height. This is not true for measuring temperatures – where zero has different means between Celsius, Fahrenheit, and Kelvin. In Kelvin, the scale is designed so zero degrees is defined as absolute zero (all molecular movement stops)
- “Count Numbers” this measures the number of times a certain event occurs. In baseball the number of hits or the number of strikeouts. In food service the number of customers who use the salad bar. In supply chain current inventory of chocolate chip ice cream or the number of orders for this flavor over the past three weeks. Count numbers are more formally “integers”. In some cases, negatives numbers may have a role, for example, if we have orders for a product in excess of the current supply, this situation can be measured as negative inventory.
Qualitative data is often the most common type of data in measuring service and has the illusion of being easy to analyze, but in fact, is full of landmines. There are three major types
- Categorical or Classification
- Ordinal categorical
- Ordinal
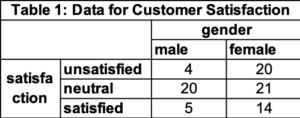
Categorical or classification refers to an attribute of some item where the number of possible values for this attribute is fixed and is inherently descriptive. As noted above, the most common is yes/no (binary). Common examples are a person’s gender and ethnicity. In an election for a congressperson, the options are the candidates on the ballot (for example Ben, Betty, or Bill), however, you can only vote for at most one of them. In customer satisfaction the options might be sad, neutral, and happy, additionally, I might know the gender of each person who responded. In food and hospitality, the categories might be possible cheese options and possible cracker options for snack plates. Typically, the record for each item has the attribute. If I have 10 patients, I record the gender and ethnicity of each one. However, the data is most often used as frequency counts. The number of items in each category. In an election, I want the number of voters for Ben, the number for Betty, and the number Bill. For customer satisfaction, I may use the data across both gender and satisfaction level. Table 1 has the frequency count for satisfaction across the two variables or dimensions (level of satisfaction and gender).
Back to the Basics: What’s the Core Purpose of Supply Chain Management?
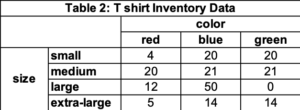
At this point, you might be saying – “count” data is used for quantitative and qualitative. You would be correct. For example, in supply chain assume my business is selling T-shirts. Each T-shirt has two critical attributes: color and size. For color, there are three options: Red, Blue, or Green. For size, there are four options: small, medium, large, and extra-large. For T-shirts, I might use the data in table for inventory analysis, where rows are size, and columns are color. This type of information is posted in Table 2.
We will address this overlap a bit later
What is Inventory Forecasting & Why your Business Needs it?
Ordinal Categorical – this is a fancy-sounding term, but it is easy to understand. It simply means there is some logical and meaningful ordering to the categories. For example, for shirt size, it is logical to order these categories from smallest to largest or largest to smallest. For customer satisfaction ordering the categories from least satisfied to most satisfied is meaningful. The same applies to pain. There is no meaningful ordering for gender or color.
Ordinal – this refers to data where the options are ordered based on some criteria – a ranking. For example, if we survey five people to find their preference for three types of lunch options (hot meal, sandwich, or salad bar), then the source data might be.
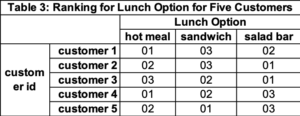
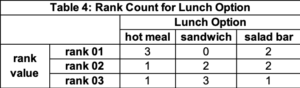
There is one row for each customer and one column for each lunch option. The value in the cell is the rank preference for this lunch option for this customer. If we look at the row for customer 1, we see a hot meal is the preferred lunch option (value of 01), followed by salad bar (02), and sandwich (03). Although these look like “quantitative count numbers”, they are not and are qualitative data. Again, we might summarize the results by counting the number of customers who selected a specific lunch option at a specific rank. Table 4 has this information. Row “rank01” tells us a hot meal is most preferred three times and salad bar twice.
Treating qualitative data as quantitative. Since we are often more familiar with summarizing and analyzing quantitative data, often we treat the numbers that are associated with the qualitative data as something we can do computation on. Two examples.
Pain scale. Assume the scale goes from 1 to 5 where 1 is little pain, 2 is a bit of pain, 3 is medium pain, 4 is disruptive pain, and 5 is intense pain. If patient Bob has a pain score of 2 and patient Ruth has a pain score of 4, people often say Ruth’s pain is twice Bob’s (2= 4/2 a ratio). However, if said Bob’s pain score was “little” and Ruth’s was “disruptive”, we would never use the ratio. It may well provide some insight to say twice as much pain, but it can be misleading.
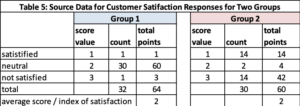
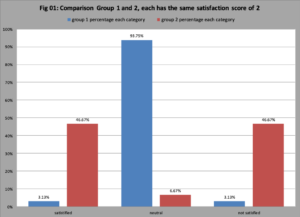
Measuring Customer Satisfaction. A common method to this ordinal categorical data quantitative is to assume values to each level of satisfaction. If I have three categories: not satisfied, neutral and satisfied where I assign the values 3 to not satisfied, 2 to neutral, and 1 to satisfied; a common analysis method to find the average score – often called the index of satisfaction. This approach can drive an erroneous conclusion. In Table, we have the frequency count for satisfaction for two groups. The average or index of satisfaction score is identical which might drive the conclusion the response pattern is the same. However, in the graph of responses (figure 01), we see the response pattern is very different. Group 1 is clustered around neutral. Group 2 is bimodal – split between “not happy” and happy.
Why is Demand Forecasting important for effective Supply Chain Management?
Enjoyed this post? Subscribe or follow Arkieva on Linkedin, Twitter, and Facebook for blog updates.





