After we have done the work to get structured data out of the unstructured data, through NLP and text processing, we can still benefit from using Natural Language Processing to get further insights.
In the previous blog, we talked about some examples of how NLP can group unstructured documents and pieces of text to get them in a structured manner. We can still use NLP to find insights in this data.
In this blog, I will talk about how utilizing a semantic parsing method can help a less experienced user transform their data questions into advanced database queries, and how it can help detect errors in datasets.
NLP for Databases
In the supply chain sector (as well as in other sectors), databases are a big part of daily operations. They hold valuable information and can be invoked at any time. Databases keep track of all sorts of enterprise level information – like inventory and operational info such as the bills of materials of thousands of products.
The way that NLP can improve this process is by preparing the data that is destined for databases as in the first section, and by generating a coherent structure and facilitating the ease of use of the data inside.
Semantic Parsing
A very database-specific example for database management and NLP is semantic parsing.
Semantic parsing lets users that are less experienced with database environments and programming languages such as SQL (Structured Query Language) be able to talk and work with relational databases.
Simple questions can be translated into more complex queries by the semantic parsing of the questions. However, these kinds of models are more in their infancy stage and have yet to be developed on a larger scale.
An example of how semantic parsing could work out is being shown in the next picture. It is an example of the SParC dataset, a context-dependent/multi-turn version of the Spider task, written by Yale students. Based on available datasets, a model is being created which lets the user translate simple questions into more complex SQL queries.

Finally, a more practical example of how a user can run SParC on their own schema, can be found here.
Error Detection in Datasets
The data that is being placed in a database, or internal data source like Excel, does not always have correct data. Internal raw data, for example data that is extracted out of a system, or internal flat files, could be incomplete and unstructured.
Different models could be applied to find this incomplete data, tag, and divide the data into different categories, and followed by an analysis of the data.
In this section, I will be diverging a bit from purely NLP applications. As NLP is mostly being run on larger pieces of text, we will need to look at other examples. Because the next examples are highly related to the topic of data management for supply chain companies, I’ve decided to include them in the blog.
While there are general-known methods such as finding missing values, other statistical and machine learning examples could also be used to find inconsistencies in data.
Error Detection
By error detection, I mean finding pieces of text and information that deviate from the general context. Finding these errors could either be done by statistical methods, where one could search the outliers of a certain dataset, and other (deep learning) methods which find data that is not relevant to the other present data.
A use case of the statistical outlier method could be the daily turnover of a local business. If they have a steady turnover every day, but one day they seem to have had little sales due to unforeseen reasons, the turnover of that day would be an outlier.
In textual data, anomalies like these could also be found. In a larger dataset, we could scan to see which products are more likely not to be relevant to the core business.
Most errors in datasets are coming out of three types of errors. The first type is transcription errors; these errors are mostly the result of typos, repetition, and deletion. The second type is transposition, where numbers are wrongly sequenced. A fun fact is that when you write a number in the wrong sequence, the difference between that number and the original number will always be divisible by 9.
A third common way of entering errors is unitization and/or representation errors.
A model could be created that learns which products are more likely to be part of the set, and which products aren’t. In real life scenarios, these words/data could be flagged and manually removed by the consultant.
Examples
Using neural networks to find errors in spreadsheets: Searching where numbers are entered instead of formulas.
These errors can be quite costly. As data in the supply chain is changing every day, multiple spreadsheets and other data sources evolve. It is important that the data in that data source evolves as well.
Finding format errors in structured datasets: For example, wrongly written dates (different formats), missing parentheses or other punctuation like extra spaces.
In some cases, these errors can be innocent, as most programming environments seem to recognize different format inputs. In databases, and in SQL, dates are recognized in different formats.
Other errors, such as extra spaces, can be more difficult as these string values can be grouped for data aggregation.
Finding this data could save the consultant of supply chain software a lot of time when setting up the software in development and even when going live into production.
It could help the consultant to find corrupted or tampered data, data that is being found in the wrong places. Some sort of data diagnostics could be setup up to:
- Find tampered with or corrupted data, data that is being found in the wrong places.
- Save the consultant and the client a lot of time in the go-live phase.
- Set-up data diagnostics for the client, as human supervision of each data entry is close to impossible in most cases
String matching and editing distance: A second example is different variations of the writing of the data (transcription errors).
It happens often when data is entered manually and with small spelling mistakes.
One of the multiple solutions to this problem could be string matching. I will be talking about string matching in general, and a more specific example called the “FuzzyWuzzy” library in Python.
FuzzyWuzzy is a pre-coded module that data engineers can apply in their code that uses the Levenshtein Distance. The Levenshtein Distance is an algorithm that calculates a number that indicates how different strings are.
In practice, this can be used by defining a set of data that is accepted as correct. New input data could be analyzed through the library to see which strings in the initial dataset, and the input dataset matches most.
As a limited example, we can refer to the coffee industry. It could be that some pieces of data are incorrectly spelled, but it could also be that they are written in a different manner. The same drink could be written as a ‘Latte’, or as a ‘Cafe Latte’.
Imagine we have the following limited dataset:
- Espresso
- Cappuccino
- Macchiato
- Latte
- Iced Coffee
And in the tampered dataset, there are different pieces of data that are incorrectly written:
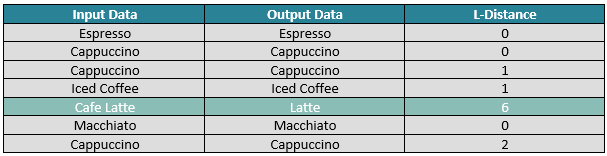
With the highlighted example, we could think this is a big distance, but if we compare to the example Macchiato we get a Levenshtein distance of 8. As Latte is already being found in both strings, the distance is much smaller than other examples {Espresso: 10, Cappuccino: 9, Iced Coffee: 10}.
This is a simple, but in my opinion, strong example. This is something a consultant could manually do, but which could save a lot of time if done automized. A consultant can always do the checkup of changed items, but doesn’t have to do the actual work themselves. In practice, NLP and string matching go much deeper than this, this example is also less machine learning based than other examples one could find.
For an example of the FuzzyWuzzy Library being used in practice, you can visit this article.
Next Blogs
The next blogs should be very interesting.
I will be talking about how NLP can benefit the supply chain when applied on external data.
There are multiple powerful possibilities of using NLP on external data.
For starters, we could use sentiment analysis to discover the general sentiment your public/clients have about your product and/or company. As this will be applied on reviews and social media mostly, this will generally be applicable for B2C (business-to-consumer) enterprises.
Another possibility is web scraping different news, market trends, and other informational websites which have info available of the supply chain sector. Automating the scraping of this information will save a lot of time keeping up with the general evolution of the sector and competitors, and can give focused, relevant information.





