In a previous blog, I have given a short introduction to the field of Natural Language Processing and what its main subfields are.
We’ve talked about supervised learning first, where the models get fed with input-output pairs and make predictions on new inputs. The second variant was unsupervised, where the model gets fed unlabeled data and should find structures in larger pieces of unstructured text. The last variant is self-supervised learning, where the model gets to make predictions on missing or non-existent pieces of text.
In blogs 2 and 3 we will focus less on the different fields of NLP, and more on business applications.
In this Forbes article, we read the problem of unstructured enterprise data. Analysts at Gartner stated that more than 80% of enterprise data is unstructured.
We know how to deal with structured data but working with unstructured data might be a bit more time consuming and challenging. There are multiple solutions that NLP offers to transform your unstructured enterprise data to structured data.
In the next blogs, we will talk about some examples of how NLP can help the company analyze and improve internal data, and how it can do that with external data as well. Both parts will focus on how we can transform unstructured to structured, and what the possibilities of NLP are on structured data, to get better insights and find unusable data entries.
For this, I tried to focus mostly on business use-cases, and less on the technical aspect of it.
Now, in this blog I will be giving two examples on how to use NLP on unstructured internal data, in the next one we will pick up structured data and show how we can work from there. This will be focused on internal data. The last two blogs will be about these possibilities with external data, such as market trend sites.
Unstructured internal data examples:
- NER models
- Planner comment analysis
Structured internal data examples:
- Databases
- Error detection & string matching
Named Entity Recognition (NER) Models
Named Entity Recognition (NER) Models can be described as models which can classify pieces of text into categories. Mostly a user trains a model to recognize different entities in a text, and to be able to classify those entities into different categories.
In the supply chain industry, a lot of documents are passing by every day. From mail, to purchase order requests from a platform, questions by employees (and clients), and much more.
In this scenario, NLP could be used to automate the process of purchase order requests and other types of communication with internal and external stakeholders.
Mail can be divided into categories according to their subject, and the text itself could be again classified and processed to get useful information for the daily operations and the supply chain in general. Also, the information could be processed much faster and more efficient when classified.
Below is a basic example of how a mail/purchase order could be classified. The model could recognize the date, the client’s name, the address, the subject of the mail, about which products the client is talking, etc.
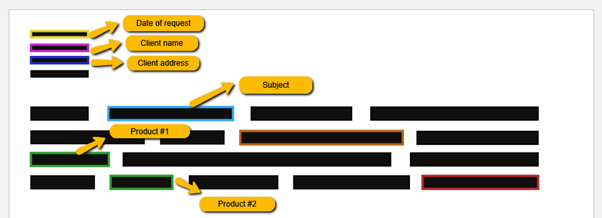
With the current given possibilities, many documents such as invoices can be analyzed to give suppliers and manufacturers insights into what their supply chain needs and lacks. The categorized information could also be automized into the operations.
Hitachi Solutions, a business application consulting firm and solutions provider, claims that this info can be used to upgrade multiple steps in the supply chain process, and make logistical changes to optimize efficiency.
Planner comment analysis
Planner comment analysis is a very interesting subject to be looked at for supply chain companies. In an article written by T.S. Krishnan and Archisman Majumdar, we see the possibility to analyze and use information shared by the supply and demand planners.
As per the article, the analysis of this model is based on 4 steps.

The first step is to harvest all the comments made by the planners. These will later be divided into different keywords, and irrelevant parts will be filtered out. It is these first two parts which I earlier described in the first blog to be very important. The cleaning and vectorizing makes sure the model is not being polluted with irrelevant data that could mess up or slow down the analyzing part.
The next part is grouping the similarities. In this example, we group the different reasons for supply chain interruptions. Topic modeling methods can be applied to cluster reasons that are similar.
Lastly, the framework can provide associations among supply chain interruptions with a particular market or vendor. Such associations are useful to identify the source of the interruption.
This planner comment analysis framework can save the company a lot of time analyzing all the different comments the planners made over a period and see the big picture. Also, predictions and proactive decisions could be made. As these comments can rack up to the hundreds of thousands, an enterprise could gain better insights, find correlations and save months of time by having them grouped and analyzed.
For more on this, visit: https://cmr.berkeley.edu/2021/01/managing-supply-chain-risk/
Concluding Remarks
These examples are just the tip of the iceberg. There are more text mining possibilities to transform unstructured data to data that is ready to be used by machine learning algorithms for further analysis.
Other examples are:
- Keyword Extraction: where the model finds the most relevant and important pieces of a larger text.
- Intent Classification: to quickly identify intents of customers and other stakeholders.
- Lemmatization: to group together different variations of words and text, so they can be seen and analyzed as a single item. For example, studying, studies and study, all refer to the same group “study”.
- Even Automatic Summarization is a possibility, where the model could create short conclusions based on a larger part of text.
Finally, I want to mention an interesting technique that could be used for automatic summarization and other NLP areas.
I’m talking about word vectorizing models, such as Word2Vec. What Word2Vec basically does, is that it gives the word embeddings in the form of mathematical vectors, based on the context it has in past appearances.
Based on this vector, relationships can be found between words, expressed in a cosine similarity score.
A famous example of this is the equation “King – Man + Woman = Queen”, where we can subtract the vector representing man from the king vector, add the vector of woman to that, and the model tells us we end up with the vector of queen.
Of course, these techniques can also be used for external data. More on this later.





