When trying to forecast demand for the future, it is important to understand the variability in the underlying dataset. A highly variable data set might have no recurring pattern in it and therefore be hard to forecast. While there is no guarantee that a data set with low variability is inherently forecastable, it does reduce the odds of getting very high forecast errors.
What is Variability and How Can it Be Used in Forecasting?
Variability is typically calculated as a Coefficient of Variation (or COV). For a more detailed understanding and to allow us to stay on subject, read this blog titled, “Do You Use Coefficient of Variation to Determine Forecastability? Companies often calculate this based on historical demand data. In the absence of true demand data, this is often calculated based on outbound shipment history.
Read More: Do You Use Coefficient Of Variation To Determine Forecastability?
How does supply disruptions affect business operations?
When shutdowns or other supply disruptions happen as a planned event, a company might deal with it via a pre-build of stock. This is no different from pre-build of anticipation stock in advance of a peak demand period where the demand exceeds the company’s capacity to make a product. In this case, it is expected that the demand can be met by this extra inventory.
Sometimes, these shutdowns or supply disruptions are unexpected. In most cases, they are also minor (may last a day or two). But, in some cases, they can be major as well. In extreme cases, they can last a month or two. Consequently, in the absence of any pre-buildup of inventory, this can result in a lot less demand being satisfied.
Read More: How to visualize the Product-Volume-Variability-Velocity Matrix
If we are to calculate demand variability, the extremely low demand period can then result in high values of variability. This is illustrated in the example below.
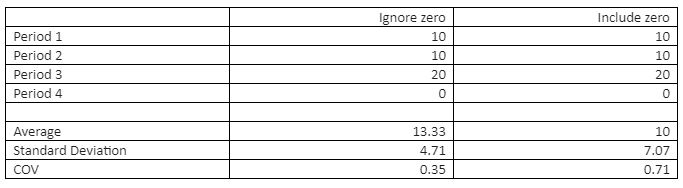
As can be seen in the simple example above, the standard deviation of demand is 1.5 times in the case where we consider the 0 versus where we do not. The portion of the safety stock that comes from the variance of the demand will then also go up proportionately by a factor of 1.5. This is too extreme for the normal months (where this shutdown does not happen) and too little for when it does happen.
How Can We Account for Such Instances?
One way to deal with this is to ignore the zero periods. Another is to treat these shutdown periods as outliers and do some outlier removal. For example, one might replace the 0 in the period with the shutdown with the average of the periods around it. This will eliminate this very high standard deviation and keep the safety stock realistic.
Read More: Three Steps to a Better Statistical Forecast Setup
The same outlier removal process can be applied as a history clean up step before forecasting. You can read about it here.
Enjoyed this post? Subscribe or follow Arkieva on Linkedin, Twitter, and Facebook for blog updates





